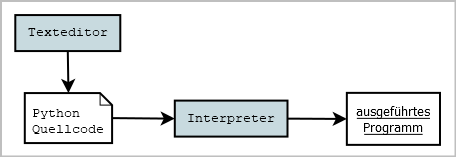
In meinem heutigen Artikel möchte ich mich der Frage widmen, wie man denn ein zufälliges Labyrinth erzeugen kann. Dazu stelle ich vor, wie ich diese Aufgabe umgesetzt habe und einen Python Labyrinth Generator implementiert habe.
Was man grundsätzlich zum Einstieg in Python benötigt und wie man sich eine entsprechende Entwicklungsumgebung unter Windows aufsetzt habe ich bereits in früheren Artikeln beschrieben, wer mag kann dort gerne reinschauen! (Teil 1, Teil 2). Eine solche Umgebung habe ich für mein Labyrinth mit Python verwendet.
Mein Beitrag gliedert sich wie folgt:
Erste Schritte zum eigenen Labyrinth Generator
Doch nun zurück zum Python Labyrinth Generator: Wie erzeuge ich ein zufällig generiertes Labyrinth? Dazu habe ich mir zuerst eine Struktur überlegt, welche das Labyrinth repräsentiert. Es bietet sich an, den Datentyp Liste zu verwenden. Listen lassen sich auch verschachteln, so ist es möglich das Labyrinth zeilenweise im Speicher zu hinterlegen. Mein Labyrinth hat also die Datenstruktur einer Liste von Listen. Die äußere Liste enthält die Zeilen des Labyrinths, und jede Zeile wird durch eine innere Liste repräsentiert, die die einzelnen Felder dieser Zeile enthält. Jedes Feld wird nun durch einen bestimmten Wert repräsentiert, der den Status des Feldes im Labyrinth angibt.
Das Ganze initialisiere ich beim Klassenaufruf wie folgt:
class Maze:
length = 0
width = 0
PATH = "."
WALL = "w"
UNKNOWN_SPOT = "u"
__wall_todo_list = []
def __init__(self, length, width):
self.length = length
self.width = width
self.maze = []
for i in range(length):
line = []
for j in range(width):
line.append(Maze.UNKNOWN_SPOT)
self.maze.append(line)Code-Sprache: Python (python)Dieser Python-Code definiert das Labyrinth als eine Klasse namens Maze und enthält die Methode init(), die beim Erstellen eines neuen Objekts der Klasse aufgerufen wird. Die Methode initialisiert ein neues Labyrinth mit einer bestimmten Breite und Länge die dem Konstruktor zu übergeben sind. Jedes Feld im Labyrinth wird mit dem Wert für UNKNOWN_SPOT initialisiert, repräsentiert durch ein einzelnes Zeichen. Wir haben jetzt also eine zweidimensionale Liste in gewünschter Größe des Labyrinths (Länge * Breite), in der jedes Feld noch unbekannt ist. Jedes Feld wird grundsätzlich durch ein einzelnes Zeichen näher spezifiziert.
Die Klassenvariablen enthalten neben Länge und Breite, sowie den drei Typen von Feldern (Pfad, Wand oder Unbekannt) auch eine Hilfsliste __wall_todo_list = []. Die Verwendung dieser Liste erkläre ich später.
Da unser Grundgerüst jetzt steht, können wir mit der Erzeugung eines Zufallslabyrinths beginnen.
Beginn der Erzeugung per zufälligem Startpunkt
Um ein Labyrinth zufällig zu berechnen gehe ich wie folgt vor: Zu allererst deklariere ich mir eine Funktion gen_random_maze(self) in der alle weiteren Schritte erfolgen und den eigentlichen Python Labyrinth Generator enthält. Die im folgenden gezeigten Codeausschnitte liegen, sofern nicht explizit anders dargestellt, alle in dieser Funktion.
Anschließend initialisiere ich den Python-eigenen Zufallsgenerator mit random.seed(). Diesen rufe ich ohne Parameter auf, was den Zufallsgenerator mit der aktuellen Systemzeit initialisiert und somit eine unterschiedliche Sequenz von Zufallszahlen bei jedem Programmstart erzeugt.
Anschließend generiere ich sowohl eine zufällige Längen- als auch Breitenkoordinate die innerhalb des noch unbekannten Labyrinths liegen. Das somit zufällig gewählte, innere Feld deklariere ich als Pfad. Alle vier Felder, die unmittelbar an diesen neuen Pfad angrenzen und noch unbekannt sind deklariere ich als Wand (Letzteres habe ich ausgegliedert in eine interne Hilfsfunktion).
Die so erzeugten, neuen Wand-Felder setze ich auf unsere eingangs erwähnte Hilfsliste __wall_todo_list. Diese Liste werden wir im weiteren Verlauf heranziehen um weitere Felder zu bearbeiten. Jeder Eintrag dieser Liste muss abgearbeitet werden, sie dient also als Todo-Liste.
def gen_random_maze(self):
rand_length = random.randint(1, self.length - 2)
rand_width = random.randint(1, self.width - 2)
self.maze[rand_length][rand_width] = Maze.PATH
self.__set_neighbouring_unknowns_as_walls([rand_length, rand_width])
[...]Code-Sprache: Python (python)def __set_neighbouring_unknowns_as_walls(self, coord):
if self.maze[coord[0] - 1][coord[1]] == self.UNKNOWN_SPOT:
self.maze[coord[0] - 1][coord[1]] = self.WALL
self.__wall_todo_list.append([coord[0] - 1, coord[1]])
if self.maze[coord[0]][coord[1] + 1] == self.UNKNOWN_SPOT:
self.maze[coord[0]][coord[1] + 1] = self.WALL
self.__wall_todo_list.append([coord[0], coord[1] + 1])
if self.maze[coord[0] + 1][coord[1]] == self.UNKNOWN_SPOT:
self.maze[coord[0] + 1][coord[1]] = self.WALL
self.__wall_todo_list.append([coord[0] + 1, coord[1]])
if self.maze[coord[0]][coord[1] - 1] == self.UNKNOWN_SPOT:
self.maze[coord[0]][coord[1] - 1] = self.WALL
self.__wall_todo_list.append([coord[0], coord[1] - 1])Code-Sprache: Python (python)Nun, da wir einen zufälligen Startpunkt sowie eine initiale Hilfsliste haben, können wir mit dem Schleifendurchlauf zur Erzeugung von Pfaden beginnen.
Zufallspfade per Schleife erzeugen
Wie oben erwähnt, werden auf unsere Hilfsliste __wall_todo_list immer die neuen erzeugten Felder vom Typ Wand gesetzt. Über diese Liste lassen wir im Folgenden unseren Algorithmus laufen und prüfen jeweils, ob sich neue Pfade setzen lassen.
Dazu passiert folgendes: Ich nutze eine while-Schleife, die so lange ausgeführt wird, wie das Attribut __wall_todo_list nicht leer ist.
Innerhalb der Schleife gibt es mehrere Schritte. Zunächst werden zwei boolesche Hilfsparameter zurückgesetzt. Dann wird ein zufälliges Element aus der Liste __wall_todo_list ausgewählt per random.choice() Methode. Dies ist die Stelle im Code an der der zufällige Pfadverlauf entsteht.
Anschließend wird überprüft, ob das zufällig ausgewählte Feld nicht an einer Außenwand liegt, indem geprüft wird, ob seine Koordinaten im inneren Bereich des Labyrinths liegen. Wenn das der Fall ist, wird gezählt, wie viele direkte Nachbarn vom Typ Pfad das ausgewählte Feld hat. Wenn genau ein Nachbar ein Pfad ist, wird das aktuell ausgewählte Feld ebenfalls als Weg markiert. Seine Nachbarn, die noch als unbekannt markiert sind, werden zudem als Wände markiert und kommen zusätzlich auf die abzuarbeitende Hilfsliste.
Zuletzt wird das nun abgearbeitete Feld aus der __wall_todo_list entfernt, um sicherzustellen, dass es nicht wiederholt besucht wird. Der Schleifenkörper wird so oft wiederholt, bis die __wall_todo_list leer ist.
Das Ganze sieht im Python Code dann so aus:
while self.__wall_todo_list:
inner_position = False
one_path_neighbor = False
rand_wall_field = random.choice(self.__wall_todo_list)
if (rand_wall_field[0] > 0) \
and (rand_wall_field[1] > 0) \
and (rand_wall_field[0] < (self.length - 1)) \
and (rand_wall_field[1] < self.width - 1):
inner_position = True
if self.__count_neighbouring_paths(rand_wall_field) == 1:
one_path_neighbor = True
if one_path_neighbor and inner_position:
self.maze[rand_wall_field[0]][rand_wall_field[1]] = Maze.PATH
self.__set_neighbouring_unknowns_as_walls(rand_wall_field)
for w in self.__wall_todo_list:
if w[0] == rand_wall_field[0] and w[1] == rand_wall_field[1]:
self.__wall_todo_list.remove(w)
Code-Sprache: Python (python)Die gegebene Methode __count_neighbouring_paths() zählt die Anzahl der Nachbarfelder des gegebenen Feldes, die vom Typ Pfad sind.
Die Methode nimmt die Koordinaten eines Feldes als Eingabe und prüft dann, ob jedes der vier umgebenden Felder ein Pfad-Feld ist. Wenn ein Nachbarfeld ein Pfad ist, wird s_paths um 1 erhöht. Am Ende der Methode wird s_paths zurückgegeben, was die Anzahl der Pfade rund um das gegebene Feld angibt. Beachte, dass die Methode darauf ausgelegt ist, nur mit Koordinaten innerhalb des Labyrinths aufgerufen zu werden, da sie ohne Überprüfung auf den Rand des Labyrinths zugreift.
def __count_neighbouring_paths(self, coord):
s_paths = 0
if self.maze[coord[0] - 1][coord[1]] == Maze.PATH:
s_paths += 1
if self.maze[coord[0] + 1][coord[1]] == Maze.PATH:
s_paths += 1
if self.maze[coord[0]][coord[1] - 1] == Maze.PATH:
s_paths += 1
if self.maze[coord[0]][coord[1] + 1] == Maze.PATH:
s_paths += 1
return s_pathsCode-Sprache: PHP (php)Abschließende Fertigstellung des Labyrinths
Die Schleife hat nun also einen eindeutigen und zufälligen Pfad durch das Labyrinth erzeugt.
Es bleiben aber noch zwei Dinge zum Abschluss zu erledigen: Das Abarbeiten eventuell noch vorhandener, unbekannter Felder sowie das Setzen von Ein- und Ausgangspfaden.
Möglichwerweise noch vorhandene, unbekannte Felder müssen noch betrachtet werden. Dazu durchlaufe ich mit zwei verschachtelten for-Schleifen das gesamte Labyrinth. Jedes gefundene unbekannte Feld wird dann entsprechend als Wand deklariert.
def __set_remaining_unknown_as_wall(self):
for i in range(self.length):
for j in range(self.width):
if self.maze[i][j] == Maze.UNKNOWN_SPOT:
self.maze[i][j] = Maze.WALL
Code-Sprache: Python (python)Im letzten Schritt müssen noch Eingangs- und Ausgangspfad erzeugt werden. Dazu habe ich jeweils eine for-Schleife implementiert, als Teil einer Methode __set_entrance_and_exit(). Diese dienen dazu, einen Eingang und einen Ausgang für das Labyrinth zu setzen.
Bei der ersten Schleife wird ein Pfad-Feld auf der linken Seite des Labyrinths gesucht, indem die Spalte an Index 1 für jede Zeile durchsucht wird. Wenn ein Weg-Feld gefunden wird, wird das Feld links davon (also Index 0, bzw. auf der linken Außenwand) ebenfalls als Pfad markiert, um den Eingang zu schaffen, und die Schleife wird beendet.
Bei der zweiten Schleife wird ein Pfad-Feld neben der rechten Außenwand des Labyrinths gesucht, indem die Spalte an Index „Breite-2“ für jede Zeile durchsucht wird. Wenn ein Pfad-Feld gefunden wird, wird das Feld rechts davon (also auf der rechten Außenwand) ebenfalls als Pfad markiert, um den Ausgang zu schaffen. Dann wird auch diese zweite Schleife beendet.
def __set_entrance_and_exit(self):
for i in range(self.length):
if self.maze[i][1] == Maze.PATH:
self.maze[i][0] = Maze.PATH
break
for i in range(self.length - 1, 0, -1):
if self.maze[i][self.width - 2] == Maze.PATH:
self.maze[i][self.width - 1] = Maze.PATH
breakCode-Sprache: Python (python)Der Python Labyrinth Generator ist fertig!
In meinem Beitrag habe ich gezeigt, wie die Erstellung eines zufällig generierten Labyrinths mithilfe der Programmiersprache Python erfolgen kann. Dazu habe ich zunächst die Datenstrukturen festgelegt und deren Initialisierung vorgestellt. Anschließend habe ich einen Algorithmus gezeigt, der in einer Schleife unter Zuhilfenahme des Zufallsgenerators Pfade innerhalb des Labyrinths erzeugt. Diese Pfade bilden letztlich einen zufälligen, aber eindeutigen und einzigartigen Weg durch das Labyrinth.
Für die Ausgabe der hiermit erzeugbaren Zufallslabyrinthe habe ich sowohl eine Methode zum String-basierten Druck auf die Konsole als auch eine Zeichnung auf eine Canvas der GUI Bibliothek tk implementiert. Wie genau das machbar ist beschreibe ich in einem anderen Beitrag. Im Ergebnis hier aber ein Bild eines mit dem hier dargestellten Codes erzeugten Labyrinths:

Ich hoffe mein Artikel ist eine nützliche Anregung für alle, die sich für das Erstellen von Labyrinthen interessieren und Python als Programmiersprache nutzen und kennenlernen möchten. Ich habe versucht die Erklärungen so zu strukturieren und verständlich darzustellen, so dass auch Anfänger in Python diesem Beitrag gut folgen können.